Adversarial attacks are the phenomenon in which models can be tricked into making false predictions by slightly modifying the input. Most of the times, these modifications are imperceptible and/or insignificant to humans, ranging from colour change of one pixel to the extreme case of images looking like overly compressed JPEGs. But it turns out even state of the art models can produce highly confident yet bizarre results to such altered inputs.
This vulnerability gives rise to two serious questions to the current state of AI:
- Are machine learning models actually understanding the abstract ideas and conceptual hierarchy of our world as we would like them to, or are they relying on statistical nuisances of the inputs to make predictions?
- Can we safely and reliably deploy our models in the production environment without the risk of exploitation and unintended consequences?
Discovered by Szegedy et. al (2013) [1] , adversarial attacks have become a major avenue of research in machine learning. The main worrying attributes of adversarial attacks are:
- Imperceptibility: Adversarial examples can be generated effectively by adding small amount of perturbations or even by just slightly modifying the values along limited number of dimensions of the input. These subtle modification makes them almost impossible to be detected by humans, but the models classify them incorrectly with high confidence challenging our understanding of how the model synthesise inputs, focus attention and learn semantics.
- Targeted Manipulation: Attack samples can be generated in a way that manipulates the model to output the exact incorrect class as intended by the adversary. This opens up the possibility of severe manipulation of the system to one's gain instead of simply breaking it.
- Transferability: Adversarial examples generated for one model can deceive networks with even different architectures trained on the same task. Even more surprisingly, these different models often agree with each other on the incorrect class. This property allows attackers to use a surrogate model (not necessarily the same architecture or even the same class of algorithm) as an approximation to generate attacks for the target model (also known as oracle).
- Lack of theoretical model: There are currently no widely accepted theoretical models on why adversarial attacks work so effectively. Several hypothesis have been put forward such as linearity, invariance and non-robust features leading to several defence mechanisms, but none of them have acted as a panacea for coming up with robust models and resilient defences.
Training a CNN on MNIST
To explore this phenomenon, let's train a purely convolutional network with 3 convolutional layers with filters count 16,32 and 64 respectively. The first layer does not do any spatial downsampling whereas second and third layer downsample with stride length of 2. Cross entropy is used as loss function and Adam is used to update the network parameters.
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, accuracy_score
class CNNet(object):
def __init__(self, learning_rate=0.001, input_dim = 28, num_class=10):
# Make hyperparameters instance variables.
self.learning_rate = learning_rate
self.num_class = num_class
self.input_dim = input_dim
self.initializer = tf.keras.initializers.glorot_uniform()
self.optimizer = tf.train.AdamOptimizer(self.learning_rate)
# Set Random seed for Tensorflow.
self.random_seed = 42
tf.set_random_seed(self.random_seed)
def network(self, X, activations=False):
with tf.variable_scope('network', initializer=self.initializer):
# Define the layers.
self.layers = [
tf.layers.Conv2D(filters=16, kernel_size=3,
strides=(1, 1), activation='relu',padding='SAME'),
tf.layers.Conv2D(filters=32, kernel_size=3,
strides=(2, 2), activation='relu'),
tf.keras.layers.Conv2D(filters=64, kernel_size=3,
strides=(2, 2), activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(self.num_class)
]
# Store activations for investigation later.
activations_list = []
# Forward pass loop, store intermediate activations.
out = X
for layer in self.layers:
out = layer(out)
activations_list.append(out)
if activations:
return out, activations_list
else:
return out, tf.nn.softmax(out)
def model(self, X, y):
# Get the logits from the network.
out_logits, _ = self.network(X)
# Calculate Cross Entropy loss.
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(
labels=y, logits=out_logits))
# Perform backprop wrt loss and update network variables.
# Instead of doing optimizer.minimize(loss), explicitly defining
# which variables are trained.
grads = self.optimizer.compute_gradients(loss)
vars_list = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES,
scope="network")
grad_list = [(g, v) for g, v in grads if v in vars_list]
optimize_op = self.optimizer.apply_gradients(grad_list)
return loss, optimize_op, out_logits
def metrics(self, y, logits, verbose=True):
# Get prediction values and flatten.
y = np.argmax(y, axis=1).flatten()
y_ = np.argmax(logits, axis=1).flatten()
confusion = confusion_matrix(y_true=y, y_pred=y_)
accuracy = accuracy_score(y_true=y, y_pred=y_)
if verbose:
print ("accuracy score: ", accuracy)
return accuracy
def train(self, train_X, train_y, test_X, test_y,
batch_size=256, epochs=100):
# Clear deafult graph stack and reset global graph definition.
tf.reset_default_graph()
# GPU config.
config = tf.ConfigProto()
config.gpu_options.allow_growth=True
# Placeholders for tensors.
X = tf.placeholder(shape=[None, self.input_dim, self.input_dim, 1], dtype=tf.float32)
y = tf.placeholder(shape=[None, self.num_class], dtype=tf.float32)
# Get the ops for training the model.
loss, optimize, out_logits = self.model(X, y)
self.saver = tf.train.Saver()
# Initialize session.
with tf.Session(config=config) as sess:
# Initialize the variables in the graph.
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
# Stochastic Gradient Descent loop.
for step in range(epochs):
# Total number of batch and start index.
num_train_batches, start = int(train_X.shape[0]/batch_size), 0
for _ in range(num_train_batches):
# Indexes for batch selection.
end = start + batch_size
limit = end if end < train_X.shape[0] else train_X.shape[0]
idx = np.arange(start, limit)
# Run optimization op with batch.
_, step_loss = sess.run([optimize, loss],
{X: train_X[idx], y: train_y[idx]})
start = end
print('='*80+'\nEpoch: {0} Training Loss: {1}'.format(step, step_loss))
# Get probabilities and report metrics.
probs = sess.run(tf.nn.softmax(out_logits), {X: test_X, y: test_y})
acc = self.metrics(test_y, probs)
self.saver.save(sess, "model.ckpt")
# Get and save representation space for training set.
probs = sess.run(out_logits, {X: train_X})
np.save('representations.npy', probs)
return step_loss, acc
def predict(self, X_test, logits=False, reps=False):
tf.reset_default_graph()
tf.set_random_seed(42)
X = tf.placeholder(shape=[None, self.input_dim, self.input_dim, 1], dtype=tf.float32)
# Get the ops for running inference on the model.
out_logits, out_probs = self.network(X)
saver = tf.train.Saver()
# Initialize a new session on the graph.
with tf.Session() as sess:
# Load the trained model into the session to run inference.
saver.restore(sess, "model.ckpt")
# Get
rep_logits, probs = sess.run([out_logits, out_probs], {X: X_test})
preds = np.argmax(probs, axis=1).flatten()
if logits:
return preds, probs
elif reps:
return preds, rep_logits
else:
return preds
The network is trained on 60000 MNIST images and achieves 98.7% accuracy on test samples. For generating and studying adversarial attack, ten samples of correctly classified digit 2 are selected.
Generating Adversarial Samples
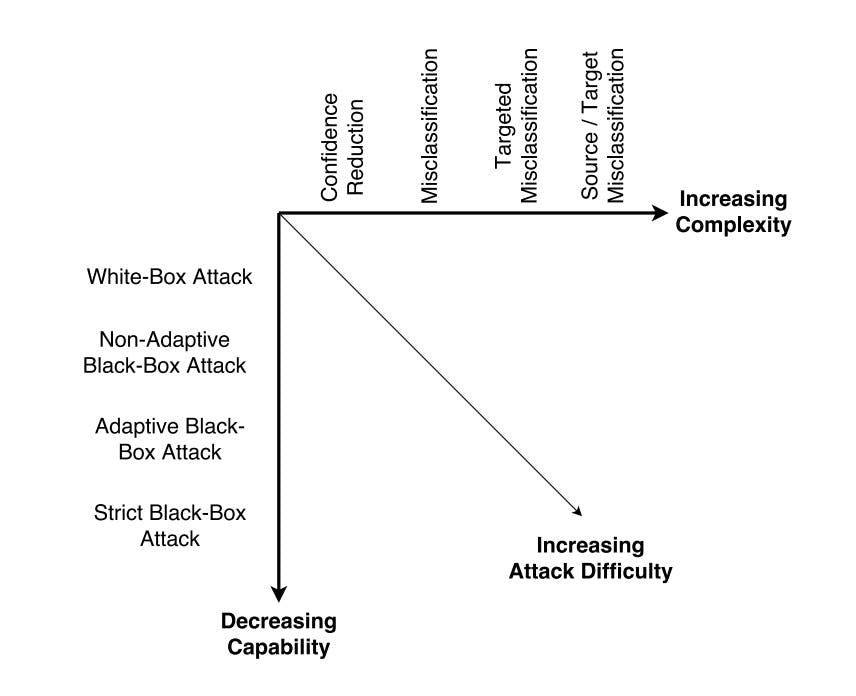
To study the attack generation mechanisms, they can be generally thought of as belonging in two dimensions:
- Targeted vs Untargeted: The adversary might want to generate attack samples that causes false classification to any other class than correct correct i.e. untrageted attack or can produce samples that forces the model to predict a specific target class.
- Blackbox vs Whitebox: In blackbox scenario, the adversary does not have access to information like model architecture, algorithm, training dataset and parameters but can probe the model with an input to observe the output. In whitebox scenario, the model is available to the attacker allowing exploitation of gradient of the loss function with respect to the input to form adversarial samples.

Fast Gradient Sign Method
FGSM is a one of the simplest yet very efficient method of generating adversarial pertubations. It is a white-box method that can produce samples to cause trageted or untargeted misclassification.
Goodfellow et. al (2014) [3] posited that linear behavior in high-dimensional input spaces is sufficient to cause adversarial perturbations. To find the perturbations, one can estimate the dimensions of the input space which are most sensitive to class change by calculating the gradient of the loss function with respect to the input. When the input is modified by changing the values of these dimensions in the opposite direction of the gradient, it maximizes the error of the network.The perturbations are calculated as:
Variation of FGSM method can be used to perform targeted attack. Here the idea is to maximize the probability of some specific target class. In this case, we are using iterative variation of FGSM as it can be used to create more powerful yet stubtle perturbations to increase the success rate of the attack.
Let's try to create adversarial inputs that will fool our network to classify digit 2 as 6.
def fgsm(model, X, target, epsilon=0.01):
"""
Implementation of Fast Gradient Sign Method.
"""
# Get logits from the model.
logits, probs = model(X)
# Create one hot encoded vectors of target.
target = tf.one_hot(target, 10)
# Loss with labels as target and logits from the model.
loss = - tf.nn.softmax_cross_entropy_with_logits_v2(
labels=target, logits=logits)
# Get gradients of the loss function wrt input image.
grad, = tf.gradients(loss, X)
# Get the direction of gradient and scale the perturbations.
perturb = epsilon * tf.sign(grad)
# Add perturbations to original image and clip if necessary.
X_adv = tf.clip_by_value(X + perturb, 0.0, 1.0)
return X_adv, perturb
def generate_fgsm(model, inputs, target, epsilon=0.001, epochs=200):
"""
Generate adversarial inputs using FGSM.
"""
tf.reset_default_graph()
tf.set_random_seed(42)
X = tf.placeholder(shape=[None, 28, 28, 1], dtype=tf.float32)
# Get the op for fgsm technique.
adv_op = fgsm(model, X, target, epsilon)
digits = inputs.reshape(-1,28,28,1)
with tf.Session() as sess:
# Restore trained model.
tf.train.Saver().restore(sess, "model.ckpt")
# Iterative FGSM.
for i in range(epochs):
digits, pert_iter = sess.run(adv_op, {X: digits})
return digits, pert_iter

There are two notable observations here:
- Inputs were successfully manipulated to be misclassified as 6. The success rate of iterative FGSM attack is high.
- FGSM technique is designed to produce pertubations along many dimensions, which might make them detectable to even human eyes. There are other white box methods that produce adversarial inputs by only modifying limited number of dimensions.
Jacobian Based Saliency Map Attack
JSMA is another gradient based whitebox method. Papernot et al. (2016) [4] proposed to use the gradient of loss with each class labels with respect to every component of the input i.e. jacobian matrix to extract the sensitivity direction. Then a saliency map is used to select the dimension which produces the maximum error using the following equation:
Let's again try to create adversarial inputs that will fool our network to classify digit 2 as 6, but this time with as little perturbations as possible.
def saliency_map(X, dtdx, dodx, eps, cmin, cmax):
"""
Saliency map function that returns score for each input dimension.
"""
# Check initial conditions.
c1 = tf.logical_or(eps < 0, X < cmax)
c2 = tf.logical_or(eps > 0, X > cmin)
# Check saliency map conditions.
c3 = dtdx >= 0
c4 = dodx <= 0
# Get 1D score by doing logical AND between conditions.
cond = tf.cast(tf.reduce_all([c1, c2, c3, c4], axis=0),dtype=tf.float32)
score = cond * (dtdx * tf.abs(dodx))
# Return score for each pixel
score = tf.reshape(score, shape=[1, 784])
return score
def jacobian_matrix(y, x, n_class):
"""
Calculate jacobian of logits wrt input.
"""
for i in range(n_class):
if i==0:
j = tf.gradients(y[i], x)
else:
j = tf.concat([j, tf.gradients(y[i], x)],axis=0)
return j
def jsma(X_adv, target_y, model, eps, cmin=0.0, cmax=1.0):
"""
Implementation of JSMA method to generate adversarial images.
"""
# Get model logits and probs for the input.
logits, probs = model(tf.reshape(X_adv, shape=(-1,28,28,1)))
# Get model prediction for inputs.
y_ind = tf.argmax(probs[0])
# Calculate jacobian matrix of logits wrt to input.
jacobian = jacobian_matrix(tf.reshape(logits, (-1,)), X_adv, 10)
# Get the gradient of logits wrt to prediction and target.
grad_input, grad_target = jacobian[y_ind], jacobian[target_y]
grad_other = grad_input - grad_target
# Compute saliency score for each dimension.
score = saliency_map(X_adv, grad_target, grad_other, eps, cmin, cmax)
# Select dimension of input and apply epsilon value.
idx = tf.argmax(score, axis=1)
pert = tf.one_hot(idx, 784, on_value=eps, off_value=0.0)
pert = tf.reshape(pert, shape=tf.shape(X_adv))
X_adv = tf.clip_by_value(X_adv + pert, cmin, cmax)
return X_adv, pert
def generate_jsma(model, X, target, eps=1.0, epochs=50):
"""
Run JSMA on input image for `epochs` number of times.
"""
tf.reset_default_graph()
tf.set_random_seed(42)
# Placeholder for single image.
X_p = tf.placeholder(shape=[28, 28, 1], dtype=tf.float32)
# Op for one iteration of jsma.
adv_op = jsma(X_p, target_y=target, model=model, eps=eps)
digit = X.reshape(28,28,1)
with tf.Session() as sess:
tf.train.Saver().restore(sess, "model.ckpt")
for i in range(epochs):
digit, pert_iter = sess.run(adv_op, {X_p: digit})
pert = digit - X
return digit.reshape(28,28), pert.reshape(28,28)

The notable observations here are:
- The major distinction of JSMA with FGSM is that it reduces the number of perturbations, making the adversarial examples far less detectable. But this comes at an expense of a higher computation cost.
- JSMA is useful for targeted misclassification attacks [2] . This is indeed observed by high success rate of misclassifying 2 as 6 in the experiment.
Extreme Blackbox Attack: One Pixel Attack
White-box attacks use gradient information of the neural networks which may not be able to an adversary in the real world situation. However, several black box attacks like surrogate models etc have shown to be quite effective in fooling networks. One of the extreme methods that demonstrates the severity of adversarial attacks is One Pixel Attack proposed by J. Su et al (2017) [5] . They successfully cause networks to misclassify labels by only modifying one pixel (the RGB values) using an evolutionary algorithm called Differential Evolution on CIFAR-10 and ImageNet datasets.
Differential evolution by R. Storn and K. Price (1997) is a simple evolutionary algorithm that works very well for optimization of complex functions where gradient based optimization cannot be used. It differs from other popular genetic algorithms by representing individuals as a vector of real numbers instead of chromosonal representations (binary, etc.) which makes them suitable to numerical optimization. New individuals are generated as
We will be using a modified Scikit learn's differential evolution implementation optimize for running on GPU. Before we can begin, we need to define a few auxilliary functions.
def perturb(xs, img):
"""
Perturb (x,y) position of img with value z.
"""
if xs.ndim < 2:
xs = np.array([xs])
# Copy the image.
imgs_cp = np.copy(img)
tile = [len(xs)] + [1]*(xs.ndim+1)
imgs_cp = np.tile(imgs_cp, tile)
for x,img in zip(xs, imgs_cp):
# Split the array into size 3 of (x,y,z).
pixels = np.split(x, len(x) // 3)
# For each perturbation tuple, apply the perturbation.
for pixel in pixels:
pixel = pixel.astype(int)
img[pixel[0], pixel[1]] = pixel[2]/256.
return imgs_cp
def predict(pixels, imgs, target_y, model):
"""
Utility function required for DE which perturbs `imgs`
with perturbation vector `pixels` and returns the confidence value
for `target_y`. The goal of DE is to minimize the value returned by this
function.
"""
if len(imgs.shape) == 3:
imgs = np.expand_dims(imgs, axis=0)
pert_imgs = perturb(pixels, imgs)
preds, probs = model.predict(pert_imgs, logits=True)
target_probs = probs[:,target_y]
return target_probs
def success(pixel, img, target_y, model, targeted=True, verbose=False):
"""
Utility function to let DE know if search is successful.
Returns True when the prediction of the perturbed `img` is not
`target_y` if `targetd` is False. Otherwise returns True only when
model prediction is equal to `target_y`
"""
if len(img.shape) == 3:
img = np.expand_dims(img, axis=0)
pert_img = perturb(pixel, img)
pred, prob = model.predict(pert_img, logits=True)
if verbose:
print('Confidence: ' +str(np.round(prob[0],4)))
if targeted:
if pred == target_y:
return True
else:
if pred != target_y:
return True
return None
def attack(img, target_y, model,maxiter=400,
popsize=5000, num_pixels=1, targeted=False):
"""
Wrapper function for performing DE and showing the final result.
"""
# Defining the range of values to be searched.
bounds = [(0,28),(0,28),(0,256)] * num_pixels
predict_fn = lambda pixels: predict(pixels, img, target_y, model)
success_fn = lambda pixel, convergence: success(
pixel, img, target_y, model, targeted)
popmul = max(1, popsize // len(bounds))
result = differential_evolution(predict_fn, bounds, callback=success_fn,
popsize=popmul,maxiter=maxiter,disp=True,
polish=False, recombination=1, tol=-1,seed=7)
final = perturb(result.x, img)
pred,prob = model.predict(final.reshape(1,28,28,1),logits=True)
plt.imshow(final.reshape(28,28), cmap='gray')
plt.show()
print('Final Model Prediction: {0} Confidence: {1}'.format(pred[0],prob[0]))
print(result)
return result, final.reshape(28,28)
result, adv = attack(mnist_twos[9], 2, model=mnist_classifier, num_pixels=5)
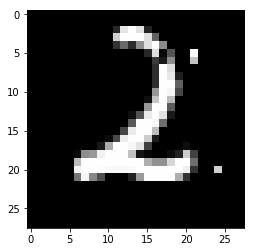
There are two notable observations here:
- It is apparent that searching for successful one pixel perturbation is a difficult task for MNIST. This is because MNIST images are grayscale two dimensional images whose space where adversarial perturbations can be found is small in comparision to 3D RGB input space of CIFAR-10 and ImageNet. Because of the exponential increase in input space, the probability of finding adversarial perturbation by search heuristics like evolutionary algorithm increases significantly. Even though finding one pixel perturbation failed, 5 pixel search was successful, suggesting larger search space indeed makes it easier to find adversarial examples.
- The difficulty of attacks with small number pertubation and search space suggests that applying domain specific transformations of complex inputs to simpler inputs as a preprocessing step might be helpful in increasing difficulty of attacks.
Analyzing effects of adversarial inputs
To analyze what is happening inside the neural networks with adversarial inputs, we can take two different perspective:
Effect on the Representation space
Deep neural networks are composed of a series of transformation of the high dimensional input space to a low dimensional representation space. It is this representation space upon which a linear classifier is employed to create a decision boundary for classification task. We can attempt to visualize the representation space by reducing the dimensionality to two using algorithms like tSNE.
To see the effect of the representation of the original input to adversarial input, lets plot their position in the representation space to observe the change from one class to another. If small perturbations push the representations slightly to cross the decision boundary, it can observed that in the visualization.

We can see in the tSNE plot that adversarial representations are jumping from the original cluster to targeted class's cluster. Since topological information of tSNE plots should be taken with a grain of salt, lets also visualize the PCA embeddings of the representation space.
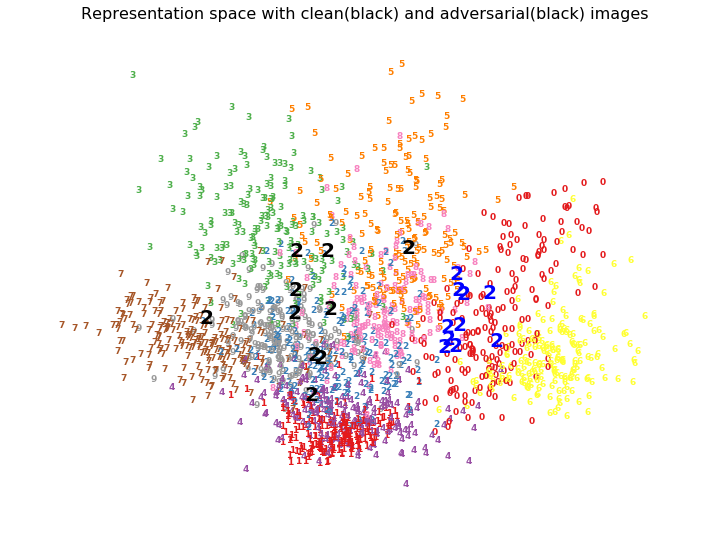
The observations here are:
- Since targeted attacks are able to change the classes to any specific intended class, it is clear that the adversarial representations are not just nudged into a neighboring cluster, but can be placed in arbitrary cluster because of which networks give incorrect predictions with high confidence.
- Adversarial examples may not just affect the final representation space but also the earlier layers significantly which cause eventual misplacement of representations in incorrect cluster leading to high confidence incorrect misclassification.
Effect on the Activation of the layers
To observe the behaviour of intermediate layers on adversarial inputs, lets visualize the differences of the activations of original input and the adversarial input of the CNN. For each convolutional layer, we subract the activations of two inputs along the kernels, and take the maximum of those differences to visualize the activation map.
The activations maps reveal how pertubations create an exploding effect of significant activation change through the layers. This exploding effect reaches the final layer and causes the representation of the adversarial example to be very different than the original input.

The observations are:
- The exploding effect of activation by slight perturbation shows that the layers are not robust and very much dependant on the right input from the earlier layers. Perhaps if the layers were resilent to slight changes in activations, this effect would be moderated.
- In some unsuccessful attacks, the activation difference tapers off through the layers and does not reach the final layer. This causes final representation to remain very close to the clean input's representation and thus misclassification is avoided.
Defense Mechanisms
Minimizing adversarial vulnerability has recieved substantial amount of research input in recent years. Several proposed defense mechanisms in the literature can broadly be categorized as:
-
Robustification: This approach is concerned with making neural networks less succeptible to adversarial attacks by regularizing against them with specialized architecture or loss functions. Two popular mechanisms are:
- Adversarial Training [1] : It modifies the loss function to augment training data with peturbed samples using FGSM technique during training.
- Defensive Distillation [6] : It is another popular approach in which a model is first trained normally with training dataset to output class probabilities. Then another identical model is trained using these probabilities as soft labels instead of class labels. This has the effect of smoothing the loss function and increasing the generalization leading to higher accuracy for adversarial examples.
Developing robustification schemes is challenging, especially due to strong transferrability of adversarial samples which allows black box attacks to bypass these defenses. Lack of strong theoritical models of adversarial attack is the major limitation in developing robustification defenses.
-
Detection: Detection mechanisms take a different route by predicting if an input contains adversarial pretubations, instead of modifying the classification model. Defense mechanisms range from classifying adversarial attacks as a separate class [7] to using generative models to reconstruct adversarial inputs into clean images [8,9] . The advantage of detection mechanisms is that they can be brought in as the first line of defense in practical settings without disturbing the main model. MagNet [8] and DefenseGAN [9] are recent examples along this approach and have produced great results, but the worry is these defenses still might be vulnerable if attackers have the knowledge of mechanism being used.
Using Autoencoders to prevent adversarial inputs
In this section, let's try to create a detection based defense mechanism that can identify apriori if the input contains adversarial perturbations. The idea is to protect the classifier from any input that does not belong to the data distribution it has not been trained on.
It has been shown that autoencoders are very good at capturing data distribution. They can reconstruct inputs with very low error if their input belongs to the training data distribution. This fact can be exploited to check if the input (adversarial or clean) belongs to the distribution that the classification model understands. When an adversarial input is fed to the encoder, it produces incorrect representation. This representation is then fed to the decoder, which generates sample from incorrect class . If there is statistical mismatch between the adversarial input and its generated output, it can be implied that input does not belong to training data distribution and was intended to fool the classification model. Here, we use Variational Autoencoder (Reference Implementation) owing to their smooth latent representation space which helps avoid degenrate reconstruction.
The following are the adversarial inputs and their corresponding generated images by VAE (bottlenect latent dimension is 2.

The accuracy of the classifier on adversarial inputs in 9.5%, whereas on the generated input, it is 21.8%. The low accuracy is to be expected as we want the VAE to fooled by the adversarial input so that it generates incorrect outputs.
Lets plot the distribution of KL divergence between adversarial and generated input AND clean and generated output to see if there is statistical mismatch. By selecting a threshold from the distribution plots, we can also calculate the success rate of detection.
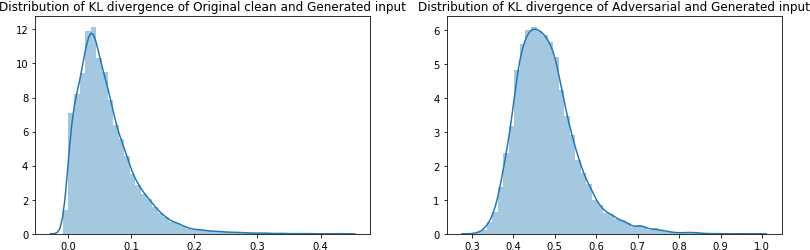
The plots demonstrate that KL divergence between the clean or adversarial input and their generated outputs. The KL divergence between clean and their corresponding generated sample is distributed from 0 to 0.3. Similarly KL divergence between clean and corresponding adversarial sample is distributed from 0.3 to 1.0. This clear distinction between the range of values of KL divergence for clean and adversarial inputs suggest that this method can be used to detect adversarial inputs.
Using the threshold of 0.3 we achieve 99% to 100% success rate for detection. The initial results on MNIST, a benchmark dataset, are very impressive. However the method needs more rigorous treatment with wide range of adversarial attack generation techniques and datasets to ascertain its generalizability.
Other potential ideas
The following are other directions of research for adversarial defense (from my limited exposure to the research and literature in this field) which might be worth exploring:
- RBF Networks are somewhat immune to adversarial samples because of their nonlinear nature [10] . If their generalizability can be improved to the current levels neural networks, they can be used as detector networks to support the decision of the main model. If the prediction label and confidence between these networks have high mismatch, the input might be adversarial.
- Adversarial attacks are considered spectacular failures because we expect the outcome state of the art models to align to human expectations. But it is apparent that they use other signals which are imperceptible to us humans to make their predictions. In the domains like computer vision, text and audio, we can regularize the classification networks explicitly to use human perceptible semantic priors like shapes and appearance instead of imperceptible signals. One possible method could be to disentangle and identify the generative factors that are being used by the model and compare to see if they align with such human priors.
Conclusion
Despite impressive accomplishments of deep neural networks in recent years, adversarial examples are stark examples of their brittleness and vulnerability. Understanding their root cause and developing robust defense mechanisms is a very important area of research.
We have to remember that models are approximations and will always look for shortcuts unless explicitly instructed not to. Just because the end result matches our expectations does not necessarily mean the models have captured the same ideas and concepts as we humans have.
In this view, adversarial attacks are not unfortunate occurrences. Instead they should be taken as a rare insight into how models actually see and synthesize our world. Their very existence calls for more theoretical study of deep learning instead of just running after empirical results.